It's 2020 and We're Still Doing Pagination The Wrong Way
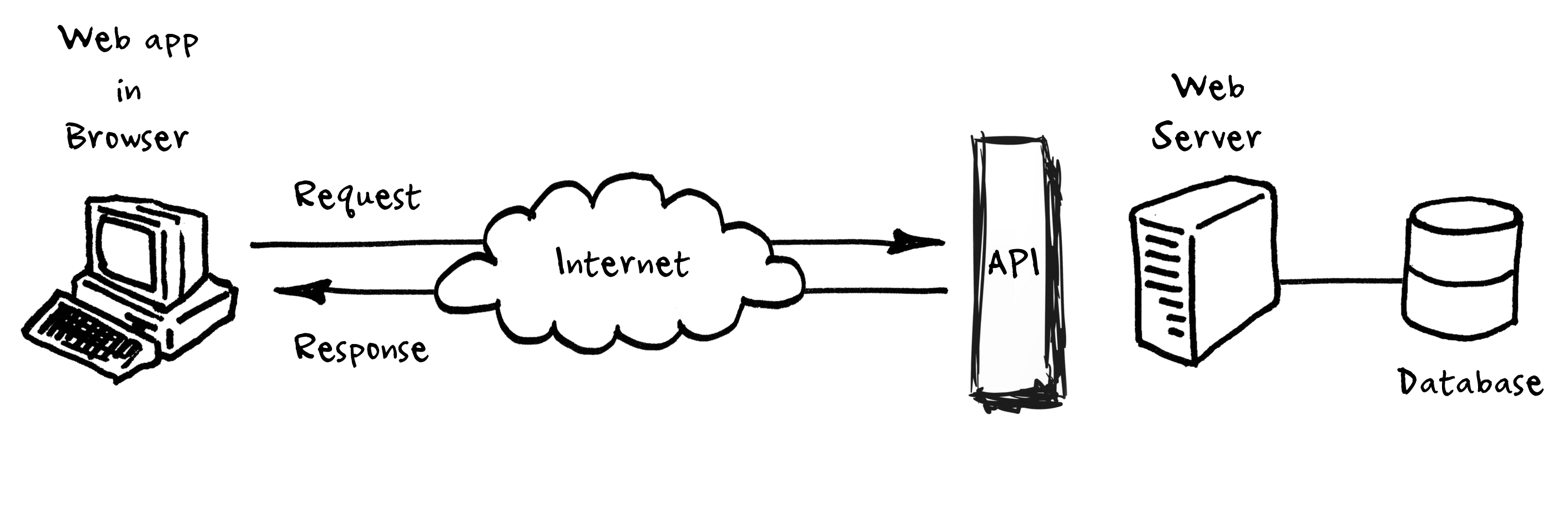
A lot of the time, when you’re making calls to a REST API, there’ll be a lot of results to return. For that reason, we paginate the results to make sure responses are easier to handle. - Atlassian Docs
Fetching a list of users, movies, contacts, etc are all examples where we fetch data using REST APIs. Based on the size of the data, these APIs are generally paginated. Before we dive in, let’s go through an example of a paginated REST API to better understand what pagination is? and Why it exists in the first place?.
If you are already familiar with it you can skip to this section which talks about different approaches to do pagination.
Let’s consider an imaginary platform called Restorrent that has around 1 million users. If you want to get data of all those users you would use the Restorrent’s REST API. You check the API docs and find this.
ENDPOINT -- https://api.restorrent.com/v1/users
DESCRIPTION -- Fetch UsersYou make a request to the Fetch Users endpoint and it takes forever to respond. You contact their support team and it turns out that their Fetch Users API doesn’t support pagination. This means when someone makes a request to this endpoint the server tries to get all the 1 million users from the database at once and if it didn’t fail there (which it should) it tries to send all those records back in the response.
There are multiple things wrong with the above implementation.
- Requesting 1 million records from a database will be an extremely slow operation which will most certainly block every other operation in the database and in most cases bring down the database server.
- Processing 1 million records at once is not something that our regular servers can do. In most of the cases, the server will run out of memory and crash.
- Receiving 1 million records in the browser and displaying those records in the UI can make the UI unresponsive.
After you submit the issue, you get a response from their support team saying that they have fixed the issue by supporting pagination in the Fetch Users API. You again check the documentation and now it looks like this.
ENDPOINT -- https://api.restorrent.com/v1/users
SUPPORTED PARAMETERS -- PAGE, LIMIT
DEFAULT PARAMETERS VALUE -- PAGE=1, LIMIT=100
DESCRIPTION -- Fetch UsersYou make a request again by calling https://api.restorrent.com/v1/users and this time you get the following response back.
{
page: 1,
limit: 100,
data: [{...}, {...}, ...]
}You only get the first 100 user records back from range 1 to 100. You make a request again https://api.restorrent.com/v1/users?page=2 and this time you get the next set of 100 users from range 101 to 200. This approach to fetch a list of records from the database works very well. You can even change the number of records you get in a single request by modifying the limit parameter. So if you need to get users in the range 700 to 800, you would supply the page parameter with a value of 70.
Now when we know what pagination is, let’s see how do we implement it.
Offset Pagination
A very common approach to add pagination support to an existing API is using the skip and limit database operator. This is how it can be done in MongoDB.
db.users.find({}).skip(0).limit(100); // 1 - returns users from 0 to 100
db.users.find({}).skip(100).limit(100); // 2 - returns users from 100 to 200
db.users.find({}).skip(200).limit(100); // 3 - returns users from 200 to 300To determine the value of skip and limit database query options from page and limit request query parameters. We can use a similar logic as shown below.
let { page = 1, limit = 100 } = req.params;
// there are more validations that you should have but I'll keep it simple here
if (isNaN(page)) {
// if page is not a number set it to 1
page = 1; // by default we send the first set of records back that's why 1
}
let skip = page * limit; // this will tell us how many records to skip to get to the desired subset(page) of user records.
const users = await db.users.find({}).skip(skip).limit(limit);
res.send({
limit,
page,
data: users,
});On receiving a request, we parse the query parameters to get the value of page and limit options. Then we calculate the value of skip and limit.
This is an easy to reason about implementation and I think that’s why it’s still the popular way of doing pagination. If the total number of records is not that big this approach is perfectly fine. But if you are working at scale or you have thousands of customers using your paginated API, this approach can slow down or block your other database operations/queries. To understand the reason behind that we first must understand how skip and limit works at the database level.
Let’s consider this query.
db.users.find({}).skip(0).limit(100);The database engine analyzes the query and concludes what it needs to do.
- Fetch records from the storage without any condition.
find({}) - From the fetched records skip 0 records.
skip(0) - Only return the 100 records back.
limit(100)
When the above three conditions are combined the database makes an intelligent decision of only fetching 100 records from the storage. Skip 0 records and return back the fetched 100 records back.
Let’s consider another query.
db.users.find({}).skip(500).limit(100);The database needs to
- Fetch records from the storage without any condition.
find({}) - From the fetched records skip 500 records.
skip(500) - Only return 100 records back.
limit(100)
When the above three conditions are combined the database makes an intelligent decision of only fetching 600 records from the storage. WHY ? Because it must skip 500 records and then it needs to send 100 from the remaining fetched records so it needs to fetch a total of 500 + 100 = 600 records.
Did you see the problem? Even though we only require 100 user records in the response. The database examined 600 user records. Imagine querying for the 1000th page which would be skipping over **1000 * 100 = 100000 ** records. In that case, we still only want 100 records in the 1000th page but the database would fetch a total of 100100 records only to return us the 100 records that belong to that specific page.
Of course, doing this without a proper index would only make things worse. Even with a proper index to support this query, this operation would be considered slow (taking a couple of seconds).
How Does Indexing Help ?
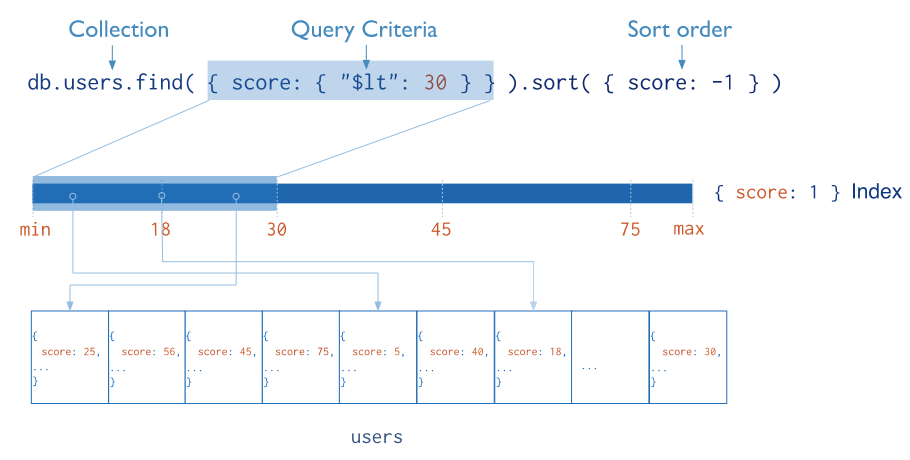
Indexes are stored in RAM and implemented as B-Tree (modified) and each node in that tree refers to a memory location in the disk where the corresponding record is stored.
Accessing RAM is an extremely fast operation whereas accessing anything on the disk (I/O) is a very slow operation. That’s why Indexes are kept in RAM.
Now imagine the database going over each of the 10000 records on the disk (slow I/O) and storing that record in the memory (taking too much space in RAM) and after that skipping the first 9900 records to return back only the last 100 records.
Accessing the I/O for 10000 records and storing 10000 records in RAM both hurt the database performance severely. Let’s consider a case where the database can make use of index to support the query.
Now the database moonwalks 🕴🏻 over 10000 nodes in the index tree (stored in RAM) and when it gets to the nodes from 9901 to 10000. It fetches the corresponding records from the disk.
Accessing the RAM for examining 10000 nodes in the index and only accessing the disk I/O for the 100 required records significantly improves the database performance.
In summary, going over thousands of records on the disk is an inherently slow operation whereas going over a thousand records in the RAM(with index) makes it way more fast. But the bottom line is that traversing/examining 1000 records when the database only needs to send 100 records results in waste of time, memory and performance of the database server.
Cursor Pagination
A better approach to pagination is implemented using a cursor value.
In this implementation, there is no concept of pages (at least at the backend). The API customer provides a cursor value and based on that value the paginated API returns a specific set of users.
What is a cursor?
If you make a request to the imaginary https://api.restorrent.com/v1/usersendpoint which is using cursor based pagination. The response will look similar to the following.
{
data: [{...}, {...}, ...],
limit: 100,
next_cursor: 101
}To get the next set of users you must pass the value of next_cursor as a query parameter to the Fetch Users API. This would make the request URL https://api.restorrent.com/v1/users?next_cursor=101 and the response to be.
{
data: [{...}, {...}, ...],
limit: 100,
next_cursor: 201
}So we can say that cursor is similar to a marker which tells the database where to send the next set of users from.
Again, to understand why this an efficient way we first must understand how it is implemented and how it works at the database level.
let { next_cursor = 1, limit = 100 } = req.params;
const users = await db.users
.find({ _id: { $gte: next_cursor } })
.limit(limit + 1);
const next_cursor = users[limit]._id; // _id of 101st user
users.length = limit; // removing the 101st user from the result
res.send({
data: users,
limit,
next_cursor,
});When the server receives this request https://api.restorrent.com/v1/users i.e without a next_cursor value. It defaults the value of next_cursor to 1.
The server sends out this database query db.users.find({ _id: { $gte: 1 } }).limit(101);
The database analyzes the query and concludes what it needs to do.
- Fetch records from the storage with a specific condition.
find({ _id: { $gte: 1 } }) - Only return the 100 records back.
limit(101)
When the above two conditions are combined the database makes an intelligent decision of only finding 100 records that match the find criteria. Since the _id_ field is indexed, the database first queries the index stored inside the RAM to directly access the node with record _id greater than or equal to 1 which is extremely fast since it is sorted. Then the database will fetch those matched records from the disk. In total, the database would only fetch 101 records from the disk.
Why 101? when we only required 100 records. The extra record outside of the limit is required to get the value of the next_cursor .
To get the next set of users the API consumer must provide the next_cursor value, in the next request to the API server.
So we send a request by calling the endpoint https://api.restorrent.com/v1/users?next_cursor=101. The server sends the database this query db.users.find({ _id: { $gte: 101 } }).limit(101);
The database analyzes the query and concludes what it needs to do.
- Fetch records from the storage with a specific condition.
find({ _id: { $gte: 101 } }) - Only return the 100 records back.
limit(101)
When the above two conditions are combined the database makes an intelligent decision of only finding 100 records that match the find criteria. Since the _id_ field is indexed, the database first queries the index stored inside the RAM to directly access the node with record _id as 101 and then 100 subsequent nodes that will be next to it that are all greater than 101 as they are sorted. Then the database will fetch those records from the disk. In , the database would fetch 101 records from the disk.
So no matter if you query with next_cursor with a value of 10 or 1000000. The database will always only examine a maximum of 101 records in the index as well as the disk. This approach makes the best use of your database indexes.
In addition to that, since it is not a good practice to let smart people guess your API implementation, you might not want the API consumers to know that you are using _id field as the cursor value. So you can encode the next_cursor value in base64 and then send it to the API consumer. When you receive the next_cursor param back you first decode it before using it in the database query.
let { next_cursor, limit = 100 } = req.params;
next_cursor = decodeBase64(next_cursor);
const users = await db.users
.find({ _id: { $gte: next_cursor } })
.limit(limit + 1);
const next_cursor = encodeBase64(users[limit]._id); // _id of 101st user
users.length = limit; // removing the 101st user from the result
res.send({
data: users,
limit,
next_cursor,
});Now the response would look something like.
{
data: [{...}, {...}, ...],
limit: 100,
next_cursor: "hgfSGE7878hkjDS&nOPNUDD09776"
}Benefits of base64 encoding?
You can always change the underlying implementation/logic of find criteria. Maybe by using some other field instead of _id and without bothering your API consumers.